
Artykuły pomocowe
Crawled – currently not indexed / Strona zeskanowana, ale jeszcze nie zindeksowana: jak to naprawić? [Case study]
To jeden z najbardziej mylących statusów w Google Search Console. Strona została odwiedzona przez Googlebota, nie ma blokady technicznej, nie jest oznaczona jako noindex, a mimo to nie pojawia się w wynikach wyszukiwania. W raporcie widzisz komunikat Crawled – currently not indexed albo jego polski odpowiednik Strona zeskanowana, ale jeszcze nie zindeksowana.
Najważniejsza rzecz, którą trzeba tu zrozumieć, jest prosta: to zwykle nie jest problem „czy Google może wejść na stronę”, tylko problem „czy Google widzi wystarczający powód, żeby ją pokazać”. Google wprost zaznacza, że strona może nie pojawić się w wynikach nawet po odwiedzeniu przez Googlebota, jeśli nie ma dla niej wystarczającej wartości albo popytu użytkowników. Google nie gwarantuje też indeksacji ani wyświetlania strony nawet wtedy, gdy spełnia ona podstawowe wymagania techniczne.
Dlatego ten status trzeba czytać nie jak błąd serwera, ale jak sygnał jakościowy. I właśnie od tej perspektywy warto zacząć naprawę.
Spis treści
- Co oznacza status Crawled – currently not indexed?
- Case study: artykuł sprzed lat, który wypadł z indeksu
- Dlaczego artykuł nie był indeksowany – 7 najczęstszych przyczyn
- Schemat naprawy krok po kroku
- Co zmieniliśmy i jaki był efekt?
- Wytyczne jakościowe dla artykułów
- Wytyczne jakościowe dla kategorii produktów
- Wytyczne jakościowe dla kart produktów
- Co warto zapamiętać
- FAQ
- Masz podobny problem?
- Warto doczytać
Co oznacza status Crawled – currently not indexed?
W Google Search Console możesz spotkać angielską wersję Crawled – currently not indexed i polską Strona zeskanowana, ale jeszcze nie zindeksowana. Niezależnie od języka znaczenie jest to samo: Googlebot odwiedził adres URL, pobrał stronę, ale na ten moment nie włączył jej do indeksu.
To bardzo ważne rozróżnienie. Jeśli strona jest blokowana przez noindex, robots.txt albo błędy dostępu, problem jest techniczny. Jeśli jednak strona została odwiedzona, a mimo to nie trafia do indeksu, trzeba ocenić jej przydatność, jakość i dopasowanie do potrzeb użytkownika. Google podkreśla, że podstawą widoczności pozostaje tworzenie pomocnych, rzetelnych i people-first treści oraz stosowanie crawlable linków, które pomagają odkrywać i oceniać strony w serwisie.
Case study: artykuł sprzed lat, który wypadł z indeksu
W opisanym przypadku problem dotyczył serwisu z obszaru zdrowia i dobrostanu psychicznego. Technicznie wszystko wyglądało poprawnie: adres URL działał, nie było blokad indeksacji, a sama strona była dostępna dla Googlebota. Mimo to część artykułów w Search Console miała status Crawled – currently not indexed i nie generowała ruchu organicznego.
Kluczowy szczegół: problematyczny artykuł nie był nowy. Powstał kilka lat wcześniej, był wcześniej indeksowany, a dopiero z czasem zniknął z indeksu. To ważna obserwacja. Google nie ocenia treści tylko raz, w momencie publikacji. Strony są regularnie ponownie analizowane, a ich widoczność może się zmieniać razem ze zmianą standardu jakości, konkurencji i oczekiwań użytkowników.
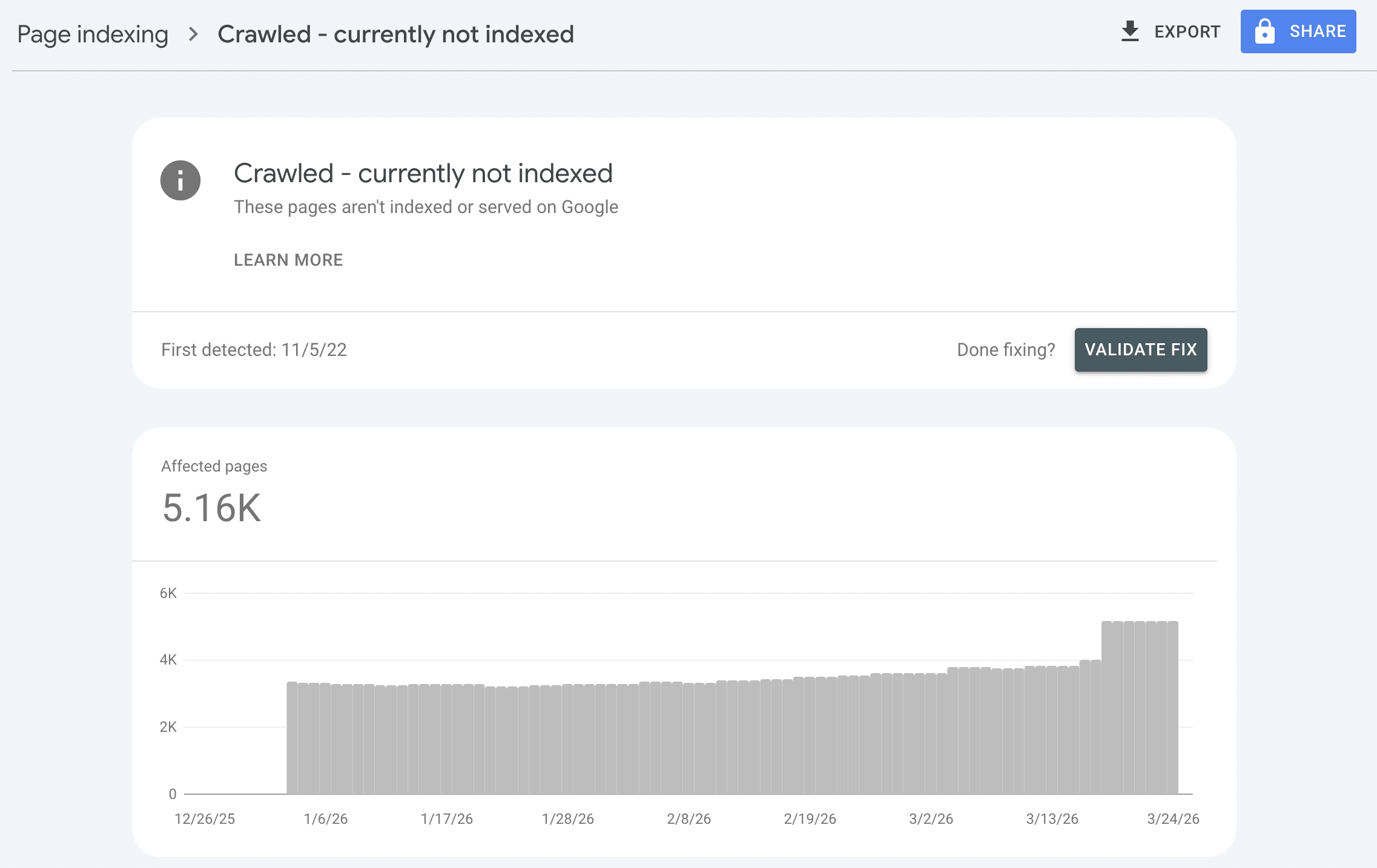
W tym case study nie naprawialiśmy „awarii”. Naprawialiśmy treść, której Google przestał ufać i której nie widział już jako wystarczająco wartościowej, by utrzymywać ją w indeksie.
Dlaczego artykuł nie był indeksowany – 7 najczęstszych przyczyn
1. Brak sygnałów wiarygodności na treści wrażliwej tematycznie
W treściach z obszaru zdrowia, finansów czy prawa zaufanie ma szczególne znaczenie. Jeżeli artykuł nie pokazuje autora, doświadczenia, daty publikacji lub aktualizacji i nie odwołuje się do wiarygodnych źródeł, Google może uznać go za zbyt słaby jakościowo, by utrzymywać go w indeksie.
2. Zbyt dużo treści „wypełniającej”, za mało realnej wartości
To częsty problem starszych artykułów. Długie wstępy, listy oczywistych porad, generyczne checklisty i akapity, które brzmią poprawnie, ale nie wnoszą nic praktycznego. Taka treść może wyglądać na rozbudowaną, ale nie przechodzi testu użyteczności.
3. Artykuł był zbyt ogólny i mało odróżnialny
Google w materiałach o people-first content zachęca do tworzenia treści, które wnoszą coś własnego: doświadczenie, analizę, dane, praktykę lub realny punkt widzenia. Artykuł, który da się streścić do kilku banalnych zdań albo napisać „z pamięci” bez żadnej ekspertyzy, ma słabszą szansę na utrzymanie indeksacji.
4. Treść była niedopasowana do intencji wyszukiwania
Nawet poprawna merytorycznie strona może wypadać z indeksu, jeśli nie odpowiada na pytanie użytkownika tak, jak odpowiadają obecnie najlepsze wyniki. Czasem problemem nie jest „jakość samej treści”, tylko to, że artykuł odpowiada w złym formacie, złą głębokością albo nie trafia w realną potrzebę.
5. Słabe linkowanie wewnętrzne
Google podkreśla, że linki pomagają odkrywać strony i rozumieć ich znaczenie w strukturze serwisu. Jeśli artykuł nie jest sensownie podlinkowany z innych podstron, a dodatkowo nie linkuje do powiązanych treści i źródeł, jego pozycja w całej architekturze serwisu staje się słabsza.
6. Brak sygnałów aktualności przy starzejącej się treści
Nie każda strona musi być stale odświeżana, ale jeśli temat się starzeje, a artykuł nadal wygląda jak materiał sprzed kilku lat bez śladu aktualizacji, Google może uznać go za mniej przydatny. Sama zmiana daty nie pomaga. Liczy się realna poprawa treści.
7. Problem z renderowaniem lub widocznością treści w HTML
Jeżeli najważniejsza część strony nie jest widoczna w wyrenderowanym HTML, Google może mieć problem z prawidłowym odczytem zawartości. Google wprost zaznacza, że jeśli treść nie jest widoczna w wyrenderowanym HTML, może nie zostać zaindeksowana.
Schemat naprawy krok po kroku
Co zmieniliśmy i jaki był efekt
W opisanym case study poprawki nie dotyczyły tylko SEO technicznego. Do artykułu dodaliśmy kontekst ekspercki, uporządkowaliśmy strukturę, usunęliśmy filler, dopisaliśmy konkret, źródła i aktywne linki. Treść przestała być „poradnikiem o wszystkim” i zaczęła odpowiadać na realny problem użytkownika.
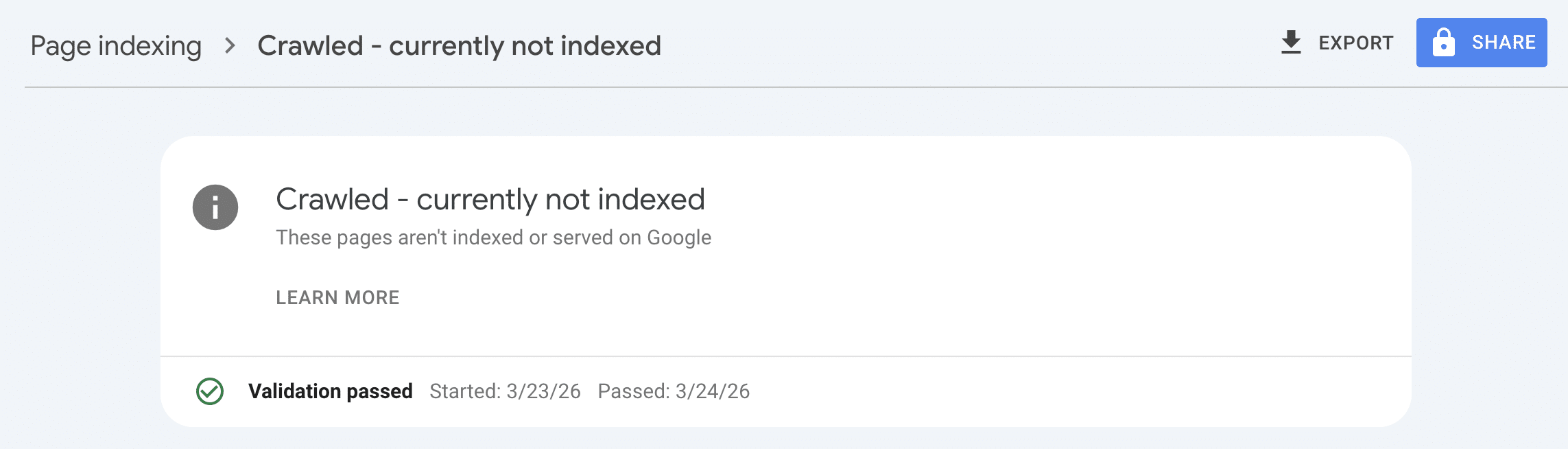
Cały proces — od audytu do złożenia prośby o ponowne zindeksowanie — zamknął się w 4 dniach roboczych. Podstrona sprawnie wróciła do indeksu. To nie jest obietnica uniwersalnego terminu, ale dobra ilustracja jednej zasady: poprawa indeksacji zaczyna się od poprawy wartości strony, a nie od samego kliknięcia „poproś o indeksowanie”.
Wytyczne jakościowe dla artykułów
Autor i wiarygodność. W artykule poradnikowym musi być jasne, kto go stworzył i dlaczego warto temu twórcy zaufać. Imię i nazwisko, rola, specjalizacja, data publikacji i data aktualizacji to dziś nie dodatki, tylko sygnały porządku i wiarygodności.
Oryginalność i głębokość. Tekst powinien wnosić własny punkt widzenia, praktykę, doświadczenie, dane lub analizę. Strony, które tylko kompilują to, co już jest w sieci, mają słabszą szansę na utrzymanie indeksacji.
Źródła i weryfikowalność. Szczególnie przy treściach wrażliwych warto linkować do źródeł, które pomagają odbiorcy zweryfikować informacje i budują zaufanie do materiału.
Aktualność. Nie chodzi o sztuczne „odświeżanie daty”, tylko o realną aktualizację: poprawienie danych, usunięcie starych fragmentów, dopisanie nowych obserwacji i dostosowanie treści do aktualnych pytań użytkowników.
Wytyczne jakościowe dla kategorii produktów
Unikalny opis kategorii. Strona kategorii nie powinna być wyłącznie listą produktów. Musi pomagać użytkownikowi zrozumieć, czym jest dana grupa produktów, dla kogo jest i jak wybrać właściwy wariant.
Dopasowanie do intencji zakupowej. Użytkownik na stronie kategorii zwykle porównuje opcje. Warto więc dodać treść wspierającą wybór: różnice między wariantami, najczęstsze zastosowania, wskazówki zakupowe.
Ograniczanie duplikacji. Wiele problemów z indeksacją kategorii bierze się z generowania wielu podobnych stron filtrów, tagów i wariantów. Tu bardzo ważne stają się canonicale, noindex tam, gdzie trzeba, i świadome ograniczanie stron bez realnej wartości.
Linkowanie kontekstowe. Kategoria powinna być centrum tematu: linkować do produktów, ale też do poradników, FAQ i treści wspierających decyzję zakupową.
Wytyczne jakościowe dla kart produktów
Unikalny opis produktu. Kopiowanie opisu producenta to jeden z najczęstszych powodów słabej jakości karty. Taki opis nie daje Google powodu, by indeksować kolejną kopię tej samej treści.
Treści użytkowników. Opinie, oceny, pytania i odpowiedzi pomagają wyróżnić kartę produktu i budują dodatkową wartość, której nie ma w innych sklepach.
Dane strukturalne. Przy produktach ważne są poprawnie wdrożone dane strukturalne, ale Google podkreśla też, że treść opisana w danych musi być widoczna dla użytkownika na stronie. Nie można „dopowiadać” w znacznikach czegoś, czego nie ma w HTML.
Warianty i niedostępne produkty. Trzeba pilnować canonicali, logiki wariantów i stron wycofanych produktów. Inaczej bardzo łatwo wygenerować dużą liczbę podobnych lub pustych stron, które osłabiają cały dział sklepu.
Co warto zapamiętać
Status Crawled – currently not indexed nie mówi: „Google nie może wejść na stronę”. Znacznie częściej mówi: „Google nie widzi dziś wystarczającego powodu, żeby utrzymywać tę stronę w indeksie”. To subtelna, ale bardzo ważna różnica.
Jeśli masz taki problem, nie zaczynaj od samego zgłoszenia URL-a do ponownej indeksacji. Zacznij od pytania, które naprawdę ma znaczenie: czy ta strona jest dziś wystarczająco pomocna, wiarygodna i użyteczna, żeby Google chciał ją pokazać?
FAQ
Czy status Crawled – currently not indexed oznacza problem techniczny?
Nie zawsze. Bardzo często oznacza, że Google odwiedził stronę, ale nie widzi wystarczającej wartości, żeby ją utrzymywać w indeksie.
Czy warto od razu prosić o ponowne zindeksowanie?
Nie. Najpierw trzeba realnie poprawić stronę. Google zaznacza, że samo zgłoszenie nie gwarantuje szybkiej ani w ogóle skutecznej indeksacji.
Czy stary artykuł może wypaść z indeksu mimo że kiedyś był widoczny?
Tak. Google stale ponownie ocenia strony, a starsza treść może z czasem przestać spełniać aktualne standardy jakości i użyteczności.
Czy linkowanie wewnętrzne wpływa na indeksację?
Tak. Google podkreśla znaczenie crawlable linków dla odkrywania i rozumienia stron w obrębie serwisu.
Masz podobny problem na swojej stronie?
Jeśli w Google Search Console widzisz strony ze statusem Crawled – currently not indexed i nie wiesz, od czego zacząć, warto zacząć od audytu jakości strony, indeksacji i linkowania wewnętrznego.
W MMarketing pomagamy uporządkować indeksację, poprawić treści, ocenić sygnały jakości i dopasować stronę do aktualnych wymagań Google. Sprawdź ofertę albo przejdź od razu do kontaktu.
Warto doczytać
- Google Search Central – jak tworzyć pomocne, rzetelne i people-first treści
- Google Search Central – podstawowe wymagania Google Search Essentials
- Google Search Central – diagnoza problemów z indeksowaniem i błędów skanowania
- Google Search Central – FAQ o skanowaniu i indeksowaniu stron
- Google Search Central – dobre praktyki linkowania i crawlable links
- Google Search Central – podstawy JavaScript SEO i renderowania treści
- Google Search Quality Evaluator Guidelines – wytyczne jakości, E-E-A-T i ocena treści YMYL